CoreWeave是新一代专注于大规模AI工作负载的专业云服务提供商,已获得超过120亿美元的融资,用于在全球各地建立数据中心。该公司专门为客户提供尖端的NVIDIA GPU资源,使他们能够高效地训练和部署复杂的AI模型并处理计算密集型工作负载。
CoreWeave计划到2024年底拥有一个涵盖28个设施的数据中心组合,包括位于新泽西州威霍肯、伊利诺伊州芝加哥、内华达州拉斯维加斯、德克萨斯州普莱诺、德克萨斯州奥斯汀、弗吉尼亚州切斯特、俄勒冈州希尔斯伯勒、佐治亚州道格拉斯维尔、英国伦敦等地的数据中心。
本文简单介绍CoreWeave GPU即服务(GPU-as-a-Service)解决方案,这些解决方案为全球AI创新者提供了支持,同时包括CoreWeave从战略性位置的数据中心到其独特GPU产品、客户群以及竞争定位等相关内容。
CoreWeave概况
CoreWeave是一家专门为大规模GPU加速工作负载提供云基础设施的供应商,该公司成立于2017年,总部位于美国新泽西州罗斯兰,目前拥有400多名员工。

CoreWeave属于提供GPU即服务(GPUaaS)或人工智能即服务(AIaaS)新类别公司。他们通过与NVIDIA等硬件供应商建立战略合作伙伴关系,提供对云端数十万个最新一代GPU的访问,从而为AI工作负载提供服务。
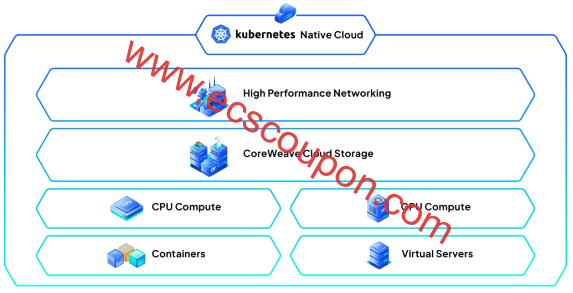
CoreWeave在AI技术堆栈的基础设施层内运行,与亚马逊网络服务(AWS)、Microsoft Azure和Google Cloud Platform(GCP)等顶级云服务提供商(CSP)有所区别。该公司通过Kubernetes原生云提供专业的云解决方案,提供GPU计算、CPU计算、容器、虚拟服务器、云存储和高性能网络等产品。
CoreWeave为计算密集型用例提供云解决方案,包括机器学习、人工智能、视觉效果(VFX)、渲染、批处理、实时像素流、生命科学、药物发现和元宇宙。其基础设施既支持训练阶段(模型从大型数据集中学习),也支持推理阶段(模型根据用户输入生成预测)。
CoreWeave提供的计算解决方案比大型通用公共云快35倍,成本低80%,其推理服务比主要通用云提供商的推理服务快8到10倍。该公司的专用网络结构旨在降低延迟并提高芯片利用率,可将延迟降低50%。此外,CoreWeave还提供增值软件和技术资源。
数据中心
CoreWeave运营数据中心组合包括遍布美国的14个设施,包括美国新泽西州、伊利诺伊州、内华达州、德克萨斯州、弗吉尼亚州、俄勒冈州和佐治亚州的设施。
CoreWeave计划到2024年底将其数据中心数量翻一番,达到28个,并进一步扩展到美国和欧洲等地区,具体是英国伦敦和西班牙巴塞罗那。
领导团队
CoreWeave由一个管理团队领导,其中包括Michael Intrator(首席执行官)、Nitin Agrawal(首席财务官)、Brannin McBee(首席开发官)、Brian Venturo(首席战略官)、Peter Salanki(首席技术官)和Mike Mattacola(首席商务官)。
财务和市场预测
CoreWeave大幅扩大了其签署的合同规模,预计其收入将从2023年的5亿美元增加到2026年的70亿美元。在过去一年中,该公司已筹集了超过120亿美元的股权和债务融资。据多方消息称,CoreWeave在最新一轮C轮投资中的估值为190亿美元。
据报道,预计到2027年,CoreWeave在人工智能领域的总潜在市场(TAM)预计将达到1600亿美元。
CoreWeave数据中心区域和位置
CoreWeave数据中心区域拥有高性能GPU集群,为超过5100万人提供低延迟的云基础设施访问,以满足AI工作负载。

目前CoreWeave在美国运营着14个数据中心,并计划到2024年底扩展到28个设施,并计划在美国和欧洲进一步发展。
| 数据中心位置 | 运营商 | 容量 |
| 新泽西州威霍肯 | — | 服务美国东部地区 |
| 伊利诺伊州芝加哥 | — | 服务美国中部地区 |
| 内华达州拉斯维加斯 | Switch,Inc | 服务美国西部地区 |
| 德克萨斯州普莱诺 | Lincoln Rackhouse | 30兆瓦,454,421平方英尺 |
| 德克萨斯州奥斯汀 | Core Scientific | 16兆瓦,118,000平方英尺 |
| 弗吉尼亚州切斯特 | Chirisa Technology Parks | 28兆瓦,250,000平方英尺 |
| 俄勒冈州希尔斯伯勒 | Flexential | 9兆瓦 |
| 乔治亚州道格拉斯维尔 | Flexential | 9兆瓦 |
| 英国伦敦 | — | 两个英国数据中心 |
| 西班牙巴塞罗那 | EdgeConneX | 主机托管 |
数据中心区域
CoreWeave Cloud目前在美国运营三个数据中心区域:美国东部、美国中部和美国西部。这些地理分布各异的区域分别由位于新泽西州威霍肯、伊利诺伊州芝加哥和内华达州拉斯维加斯的数据中心提供支持。

美国东部 –新泽西州威霍肯
CoreWeave美国东部(LGA1)数据中心区域位于新泽西州威霍肯,为美国东部纽约市大都会区超过2000万居民提供超低延迟服务,其中到曼哈顿的延迟仅为1毫秒。
美国中部 – 伊利诺伊州芝加哥
CoreWeave的美国中部(ORD1)数据中心区域位于伊利诺伊州芝加哥市中心外,服务于美国中部。
美国西部 – 内华达州拉斯维加斯
CoreWeave美国西部(LAS1)数据中心区域位于内华达州拉斯维加斯的巴杜拉大道5605号,服务于美国西部地区。作为GPU即服务(GPUaaS)提供商,CoreWeave已在此位置获得托管容量,该位置是Switch, Inc的数据中心,称为Core Campus。
网络基础设施
CoreWeave每个数据中心区域都提供来自一级全球运营商的冗余公共互联网连接,速度超过200Gbps(千兆位/秒)。此外,这些数据中心区域通过超过400Gbps的暗光纤传输相互连接,使得在CoreWeave Cloud内部的数据传输变得轻松且免费。
数据中心位置
为满足业务增长,CoreWeave一直在美国各地积极租赁或建设数据中心,包括德克萨斯州、弗吉尼亚州、俄勒冈州和佐治亚州。该公司还在国际上扩张,在英国伦敦和西班牙巴塞罗那建立了业务。
德克萨斯州普莱诺
CoreWeave在德克萨斯州普莱诺开设了一个价值 16 亿美元、占地454,421平方英尺的新数据中心设施,该设施于2023年底投入运营。该设施坐落在一个占地23.8英亩的园区内,位于德克萨斯州普莱诺科伊特路1000号林肯地产公司的林肯Rackhouse大楼内。
该数据中心拥有四个14,000平方英尺的数据大厅,另外还有50,000平方英尺的供电外壳空间可供未来扩建。

根据向德克萨斯州达拉斯县地方法院提交的文件,1000 Coit Road数据中心包括以下内容:
- CoreWeave有可能利用Lincoln Rackhouse数据中心高达30兆瓦(MW)的关键IT负载,分多个阶段进行,以适应必要的电气和机械升级
- Lincoln Rackhouse估计需要投入约9000万美元的资本支出来支持30兆瓦的关键IT负载
- CoreWeave部署的初始阶段涉及12MW
- Lincoln和CoreWeave签署了一份为期6年的主服务协议(MSA)(而非租约),同意基本租金为每月每千瓦(kW)75美元
- 根据MSA,CoreWeave同意向林肯支付超过2.6亿美元的初始30兆瓦安装费用
- Lincoln和CoreWeave还提供了两个为期2年的续约选项,总合同期限可能为10年,续约选项预计额外支付1.804亿美元
- 普莱诺市的税收优惠和减免为CoreWeave和Lincoln带来了约1.41亿美元的税收优惠
德克萨斯州奥斯汀
CoreWeave已签署一份为期8年的租赁协议,租用位于德克萨斯州奥斯汀3301 Hibbetts Road的Core Scientific数据中心,数据中心容量为16兆瓦,占地118,000平方英尺。该空间将托管CoreWeave的基础设施并支持其GPU云计算工作负载。目前,奥斯汀数据中心的运营容量为12兆瓦。
在主机托管合同有效期内,CoreWeave将向Core Scientific支付超过1亿美元,其中包括8年期限的9780万美元租赁费用。
弗吉尼亚州切斯特
CoreWeave已为名为CTP-01的数据中心签署了一份为期12年的许可协议,并附有两个5年的延期选择权。该设施由Chirisa Investments所有,并由Chirisa Technology Parks运营。它位于弗吉尼亚州切斯特菲尔德县切斯特的Meadowville Technology Parkway 1401 号,距里士满以南约15英里。
根据提交给纽约州最高法院的文件,CoreWeave最初同意以每月每千瓦115美元的价格授权18.6兆瓦 的关键电力,每年增加3%。该合同的起始月度经常性费用约为214万美元。弗吉尼亚州里士满工厂的未来扩张使得CoreWeave和Chirisa之间的合同总价值估计约为3.65亿美元。
这个全面运营的交钥匙数据中心目前提供28兆瓦的电力容量,横跨三个数据大厅和250,000平方英尺的空间。它是Chirisa拥有的88英亩大园区的一部分,其中包括相邻的土地,可支持未来建造高达100兆瓦电力容量和高达500,000平方英尺建筑面积的定制数据中心。
俄勒冈州希尔斯伯勒
CoreWeave已扩展为一家主机托管数据中心,由Flexential拥有和运营,名为波特兰-希尔斯伯勒4。该设施位于俄勒冈州希尔斯伯勒东北斯塔尔大道4915号,该市位于波特兰以西13英里(21公里)。CoreWeave数据中心拥有9兆瓦的电力分配,并支持3600Gbps InfiniBand网络。
另外,CoreWeave已与Digital Realty签订了位于俄勒冈州希尔斯伯勒的数据中心的36兆瓦租赁协议,用于在一个设施中部署数万个GPU。这个外壳就绪设施采用高密度设计,限制在一栋建筑的较小空间内,光纤长度不超过100 米(328英尺)。这种设计使CoreWeave能够创建一个GPU“大脑”,使整个GPU集群可以配置为单个系统并作为单 InfiniBand结构运行。
乔治亚州道格拉斯维尔
CoreWeave已扩展为一家主机托管数据中心,由Flexential拥有和运营,名为亚特兰大-道格拉斯维尔。该设施位于佐治亚州道格拉斯维尔的北河路1700 号,该市位于亚特兰大以西13英里(21公里)。CoreWeave数据中心的电力分配为9兆瓦。

其它美国数据中心位置
除了上面提到的美国数据中心位置外,CoreWeave还在弗吉尼亚州阿什本、佐治亚州亚特兰大、伊利诺伊州芝加哥、新泽西州锡考卡斯和加利福尼亚州圣何塞设有部署。
Equinix
CoreWeave已在美国Equinix的多个零售(IBX)数据中心部署了网络和推理型节点,这些部署利用了Equinix的多云入口和跨多个大都市区域的网络连接,使CoreWeave能够访问各种云提供商和网络服务提供商。CoreWeave存在于以下Equinix互连数据中心:
- 弗吉尼亚州阿什本: Equinix DC1-DC15、DC21。在这里,CoreWeave还可以访问Equinix阿什本公共对等交换点
- 亚特兰大: Equinix AT1
- 芝加哥: Equinix CH1/CH2/CH4
- 纽约(新泽西州西考卡斯): Equinix NY2/NY4/NY5/NY6
- 硅谷(圣何塞): Equinix SV1/SV5/SV10。在这里,CoreWeave还可以访问Equinix圣何塞公共对等交换点
Core Scientific
CoreWeave与Core Scientific签署了一系列为期12年的合同,每份合同均包括两个5年的续约选择,以确保约200兆瓦的基础设施来托管其高性能计算服务。Core Scientific将修改其拥有的多个现有的以比特币挖矿为重点的站点,以适应CoreWeave的NVIDIA GPU。这些站点的修改预计将于2024年下半年初开始,并于2025年上半年投入运营。
CoreWeave与Core Scientific签订的200兆瓦长期托管协议预计每年将产生约2.9亿美元的付款,在最初的12年合同期内总额将超过35亿美元。
TierPoint
CoreWeave已与TierPoint签署了一项长期协议,将在TierPoint的一个美国数据中心部署容量为16 MW的主机托管服务,该中心尚未透露名称。
英国伦敦
CoreWeave已承诺在英国投资13亿美元(10亿英镑),以增强该国的AI能力,这项投资将支持2024年在英国开设两个数据中心,并计划在2025年进一步扩建。此外,CoreWeave已在伦敦设立欧洲总部,作为其进军欧洲的一部分。
欧洲大陆——挪威、瑞典和西班牙
CoreWeave承诺在2025年底前投资22亿美元扩建并开设欧洲大陆(挪威、瑞典和西班牙)的三个新数据中心,这项投资是其在英国13亿美元承诺的补充,使其在欧洲的总投资达到35亿美元。
CoreWeave扩张旨在首次在该地区大规模提供先进的计算解决方案,包括NVIDIA Blackwell平台和NVIDIA Quantum-2 InfiniBand网络。该公司的欧洲数据中心将提供低延迟性能、数据主权,并将100%采用可再生能源供电。
西班牙巴塞罗那
根据CoreWeave的招聘页面,该公司在西班牙巴塞罗那有数据中心职位空缺,具体位于西班牙巴塞罗那Ctra. de la Santa Creu de Calafell, 99, 08840 Viladecans的EdgeConneX BCN01数据中心,这表明CoreWeave数据中心可能位于该市场。
CoreWeave数据中心GPU
CoreWeave主要致力于为其基于云的服务提供高性能NVIDIA GPU,并在较小程度上提供AMD和Intel的CPU,这些解决方案为客户提供强大的计算资源,既可按需使用,也可通过预留实例合同使用。

当前GPU产品
目前CoreWeave提供13个NVIDIA GPU SKU,主要分为以下几类:
- NVIDIA H100: NVIDIA Hopper H100 Tensor Core GPU是NVIDIA的旗舰数据中心GPU,专为大规模AI和高性能计算工作负载而设计。它使用Hopper架构为NVIDIA Grace Hopper CPU+GPU 架构提供支持,该架构将NVIDIA Hopper GPU与Grace CPU相结合;
- NVIDIA A100: NVIDIA A100 Tensor Core GPU是一款专为AI、数据分析和HPC工作负载设计的数据中心GPU。它是NVIDIA H100的前身,基于较旧的Ampere架构;
- NVIDIA A40: NVIDIA A40是一款数据中心GPU,用于AI、深度学习、数据分析和HPC工作负载。与A100相比,它是一种更实惠的选择,并且也基于Ampere架构,在性能方面介于A100和V100之间;
- NVIDIA V100: NVIDIA Tesla V100 Tensor Core GPU是一款专为机器学习、渲染和模拟而设计的数据中心GPU。它是NVIDIA A100的前身,基于较旧的Volta架构;
- NVIDIA RTX 系列: NVIDIA RTX A6000、A5000和A4000是专业级GPU,专为视觉效果(VFX)、渲染、模拟和数据科学等视觉计算工作负载而设计,这些GPU基于Ampere架构。
未来GPU产品
2024年,CoreWeave将扩展其产品线,包括采用NVIDIA Blackwell GPU架构的NVIDIA B200以及GB200(Grace Blackwell超级芯片)。与其前身Hopper架构相比,这种新架构可实现万亿参数AI模型,成本和能耗降低高达25倍。CoreWeave是NVIDIA Cloud Partner计划中的公司之一,将成为首批向客户提供Blackwell驱动实例的公司之一。

NVIDIA的AI 超级计算机
CoreWeave还与NVIDIA合作打造了世界上最快的AI超级计算机,该计算机在不到11分钟的时间内训练了一个具有1750亿个参数的GPT-3大型语言模型(LLM)——在基准测试中比竞争对手快29倍以上。
CoreWeave客户群体
CoreWeave为各行各业的各种客户提供服务,尤其专注于大型语言模型(LLM)构建者。

CoreWeave著名客户包括:
- 微软: CoreWeave提供云计算基础设施和NVIDIA GPU访问权限,以支持OpenAI和Azure AI工作负载的计算需求。微软是CoreWeave最大的客户之一,多年来签订了价值数十亿美元的协议;
- NovelAI: NovelAI是一项AI辅助创作和讲故事的订阅服务,是首批在CoreWeave云平台上部署NVIDIA HGX H100 GPU的公司之一。CoreWeave的H100集群使NovelAI能够更灵活地进行模型设计,更快地进行训练迭代,并每月向数百万用户提供其AI模型;
- Inflection AI:人工智能实验室Inflection AI利用CoreWeave的超级计算基础设施(由3,500多个NVIDIA H100 GPU提供支持)来训练其LLM Pi。此外,Inflection AI还与CoreWeave和NVIDIA合作,打造了世界上最大的人工智能集群,其中包括22,000个NVIDIA H100 Tensor Core GPU;
- Mistral AI:总部位于巴黎的开源AI初创公司Mistral AI使用CoreWeave的基础设施,通过NVIDIA H100 Tensor Core GPU提供快速可靠的性能。CoreWeave基础设施简化了Mistral AI的VFX工作流程并提高了效率。
CoreWeave价格
CoreWeave为NVIDIA GPU提供单点定价,每小时费用因具体GPU型号而异。客户可以在调度工作负载时选择所需的GPU、CPU、RAM和存储资源来定制硬件配置。以下是CoreWeave的NVIDIA GPU实例定价明细:
| NVIDIA GPU | 每小时成本 | 显存 |
| H100 HGX(80GB) | 4.76美元 | 80GB HBM3 |
| A100 HGX(80GB) | 2.21美元 | 80GB HBM2e |
| A100 HGX(40GB) | 2.06美元 | 40GB HBM2e |
| A40 | 1.28美元 | 48GB GDDR6 |
| NVLINK的V100 | 0.80美元 | 16GB HBM2 |
| RTX A6000 | 1.28美元 | 48GB GDDR6 |
| RTX A5000 | 0.77美元 | 24GB GDDR6 |
CoreWeave GPU即服务(GPUaaS)
CoreWeave主要与其它GPU即服务(GPUaaS)公司和面向AI的云提供商竞争,例如Lambda Labs、Denvr Dataworks、Applied Digital和Crusoe。他们提供基础设施即服务(IaaS),为需要直接访问“raw”GPU和裸机性能以执行计算密集型任务的客户提供服务,以及在GPU结构的不同部分之间移动大量数据的能力。
更广泛地说,CoreWeave的高性能计算(HPC)解决方案面临着来自DigitalOcean(收购Paperspace后)、FluidStack、Iris Energy和RunPod等公司的竞争。这些平台迎合了客户在AI之旅的早期阶段的需求。例如,DigitalOcean通过其Gradient应用程序提供IaaS解决方案和平台即服务(PaaS),该应用程序支持软件开发人员构建支持AI的应用程序的整个生命周期。
此外,CoreWeave与NVIDIA的DGX Cloud关系复杂,既涉及投资和技术方面的合作,也涉及间接竞争。它们为略有不同的细分市场提供针对AI工作负载的差异化云解决方案。