在进行GPU规格或深度学习应用程序中,可能会遇到浮点精度格式FP16和FP32。但你是否想知道它们的含义?或者为什么有些应用程序更喜欢其中一种而不是另外一种?
众所周知,计算机能够理解以二进制数字系统表示的数字以及几乎所有其它事物。然而,没有一个公式可以将所有类型的数字从一种数字系统编码到另一种数字系统,特别是在涉及浮点数时。
如果你想对整数进行编码,有两件事你必须考虑:整数的大小(非正式地可以说,数字)和符号。因此,当你听到INT8时,这意味着8位用于对整数进行编码,其中一位用于确定整数的符号,另外7位用于对整数的大小进行编码。
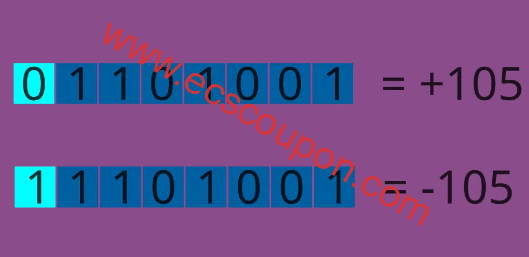
这里你可以想到唯一的困难是整数的值;因为如果你的整数很大,则需要使用范围更广的格式才可以表示。
但当涉及到浮点数时,事情会变得很有趣。我们用三组位来表示浮点数:符号(始终占用一位)、指数(或幅度,这表明数字有多大)和尾数(精度,这是告诉数字的精度或位数)。浮点数格式之间的区别在于有多少位专用于指数和多少位专用于尾数。
什么是FP32?
几乎所有现代处理单元都支持标准FP32格式,并且通常FP32数字被称为单精度浮点。这种格式用于不需要太强调精度的科学计算;此外,它已经在AI/DL应用程序中使用了很长一段时间。FP32精度格式位划分如下:
- 1 位用于数字的符号。
- 8位用于指数或幅度。
- 23位用于尾数或分数。
FP32范围:
每种格式都有一系列可以用FP32表示的数字,并且使用FP32可以表示10^38数量级的数字,具有约7-9个有效十进制数字。

什么时候使用FP32精度?
- 任何不需要超过6位有效小数位的科学计算。
- 在神经网络中,这是表示大多数网络权重、偏差和激活(简而言之,大多数参数)的默认格式。
软件和硬件兼容性
现在使用的任何CPU和GPU都支持FP32,它在流行的编程语言中用float类型表示,例如C和C++。此外,你还可以在TensorFlow和PyTorch中分别将其用作tf.float32和torch.float/torch.float32。
什么升FP16?
与FP32不同,正如数字16所示,FP16格式表示的数字称为半精度浮点数。
FP16最近主要用于DL应用,因为FP16占用一半的内存,理论上它比FP32花费的计算时间更少,这会导致FP16覆盖的范围及其实际保持的精度显着下降。FP16精度格式位划分如下:
- 同样,1位用于符号。
- 5位用于指数或幅度。
- 10位用于精度或分数。
FP16范围:
FP16的可表示范围约为10^-8至65504,具有4位有效十进制数字。

何时使用FP16
主要用于深度学习应用,需要的数字范围比较小,而且对精度要求不高。
软件和硬件兼容性
少数现代GPU支持FP16;由于在大多数DL应用程序中倾向于使用FP16而不是FP32,所以TensorFlow通过使用tf.float16类型支持FP16,在PyTorch中通过使用torch.float16或torch.half类型来支持FP16 。
另外,在其它编程语言中,短浮点类型通常用于编码半精度浮点数。
FP16与FP32区别差异
FP16与FP32这两种格式都最适合其用途,但是当你想选择其中一种时,需要考虑以下几点内容。

范围
范围对于选择使用哪种格式至关重要。FP32具有更大的表示范围。FP32的指数部分有8位,而FP16只有5位。这意味着FP32可以表示更大的数值范围,同时也可以表示更小的数值。而FP16在表示大数值时可能会出现溢出,导致结果不准确。
精度
精度随着位的增加而增加。这意味着如果你需要精确的结果,应该使用具有更高精度位的格式,但这会增加计算的空间和时间要求。FP16相对于FP32来说具有较低的精度。FP16的小数部分只有10位有效数字,而FP32有23位有效数字。这意味着在进行计算时,FP16可能会引入更大的舍入误差,导致结果的精度降低。
由于FP16具有较低的精度和较小的表示范围,因此在一些计算密集型任务中,如深度学习中的神经网络训练,可以使用FP16来加速计算,减少内存占用。但是在某些需要高精度计算或者对数值范围要求较高的任务中,仍然需要使用FP32来保证计算的准确性。
结论
以上就是关于FP16和FP32的相关内容介绍,并对二者之间的差异进行了比较。可以看出,如果我们重视速度而不是精度,那么应该使用位数较少的FP16格式,反之亦然。
除此之外,还有双精度浮点数FP64,符号位为1、指数位11、尾数位52。值得一提的是,FP8首次出现在2022年4月,由Nvidia发布的最新一代高性能GPU架构:H100,FP8有两种形式,E5M2(指数位5、尾数位2)和E4M3(指数位4、尾数位3)。